iaGuoZhi
内存虚拟化介绍
这篇文章会介绍如何在QEMU/KVM 虚拟化中为Guest kernel和Host kernel创建一块shared memory。有了共享内存之后可以做很多用意思的事情,比如共享调度信息,共享IO队列等等。
首先简要介绍下QEMU/KVM的内存虚拟化: 在硬件虚拟化中,Guest运行时实际上有两层页表,第一层是将Guest内部的va(gva)翻译成pa(gpa),第二层是将Guest的pa(gpa)翻译成Host的pa(hpa)。
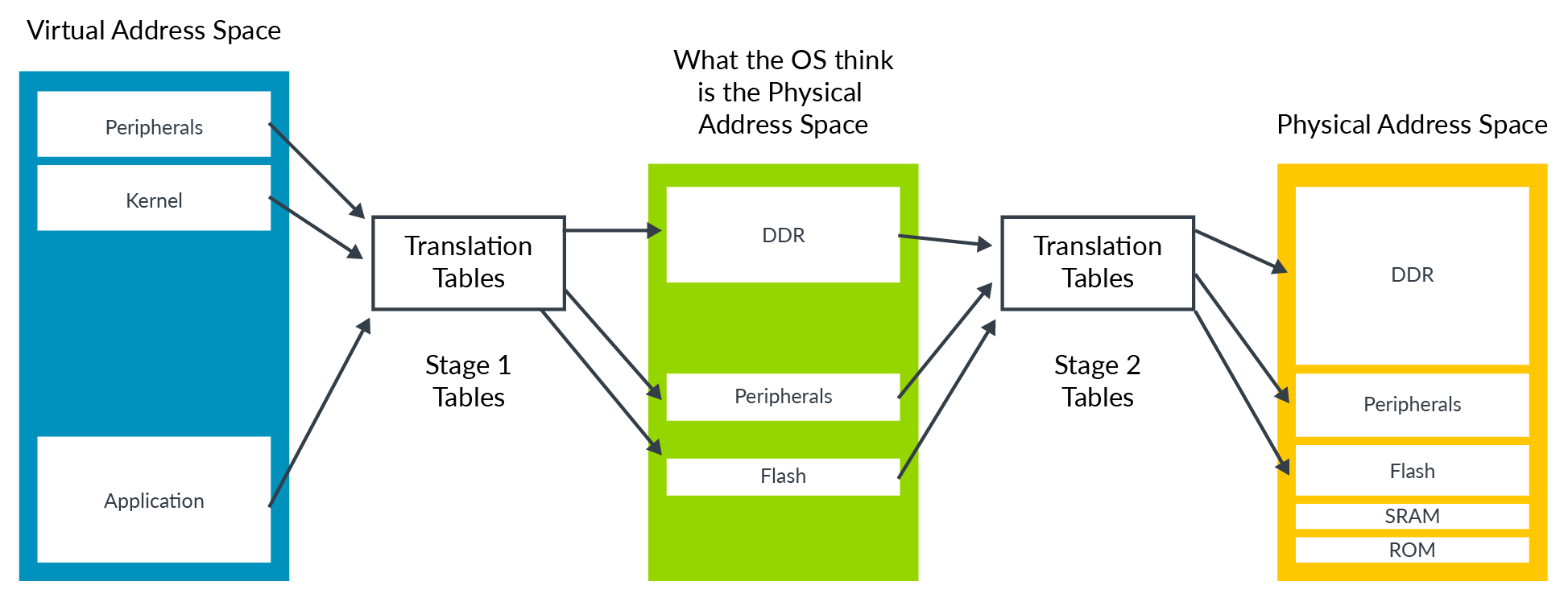
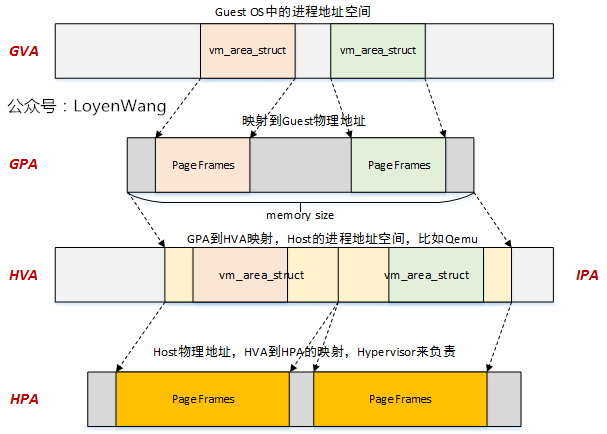
看了上面这个图,我们可能会认为内存虚拟化已经很完备了,但其实我们还需要有另一个地址: hva。这是因为
- Host 不会给 Guest的gpa直接分配hpa,而是为每一个gpa 所在的memory slot分配对应的hva。 在发生stage2 page fault的时候再根据gpa对应的hva属性进行hpa的分配
- 有了hva, Host(QEMU)可以走自己的页表访问Guest的内存
- Host(QEMU)能够通过hva和gpa之间的关系管理Guest内存信息
这里贴出一张LoyenWang制作的图来表示这四种地址的关系:
因此QEMU/KVM中现有的机制允许Host中的QEMU访问Guest的物理内存,也就是说QEMU和Guest是天然共享着内存的。这篇文章将会介绍如何进一步让KVM(也就是Host kernel)和Guest之间共享一块内存,实现这样一套机制很有意义,因为Host中大部分有价值的信息以及代码都是在kernel中的,Host kernel能够利用这块共享内存帮助虚拟机提供更多信息或者做更多的事情。
共享内存实现
我们将让Guest物理内存的8G<->8G + 1M这1M的内存共享给Host kernel。这需要更改Host kernel, Guest kernel的代码。具体代码可以在Github上看到。
由于Guest和QEMU天然是共享这内存的,Guest可以通过gva拿到gpa,QEMU也能够通过hva拿到gpa。而QEMU只不过是Host里的一个普通进程,Host肯定也是能够看到QEMU内存的,也就可以看到虚拟机的内存。因此我们这个共享内存的实现其实只需要让KVM(Host kernel)知道如何访问到虚拟机的gpa对应的物理内存即可, 缺少的是一个正确的Host kernel va。
于是我们的代码需要做两个事情:
- Guest 将一个gpa传给KVM。
- KVM将gpa转化成Host kernel里面的va。
Hypercall
将gpa传给KVM只需要在KVM里面添加一个Hypercall,在Guest里面通过调用该hypercall将gpa传给KVM即可。
Host:
int kvm_emulate_hypercall(struct kvm_vcpu *vcpu)
{
---
case KVM_HC_EXPOSE_SHM: {
64 gpa = a0;
break;
}
---
}
Guest:
/* 1M shared memory */
static u64 SHM_SZ = 1 << 20;
void expose_shm(void)
{
void *shm;
shm = kmalloc(SHM_SZ, GFP_KERNEL);
*(int *)shm = 0x1111;
*(int *)(shm + (1 << 10)) = 0x2222;
*(int *)(shm + (1 << 11)) = 0x3333;
pr_info("%s %d Content to KVM: %x %x %x\n",
__func__, __LINE__, *(int *)shm, *(int *)(shm + (1 << 10)),
*(int *)(shm + (1 << 11)));
kvm_hypercall1(KVM_HC_EXPOSE_SHM, virt_to_phys(shm));
}
(方法一)利用hva
第一件事情很简单,第二件事是KVM将gpa转化成Host kernel里面的va。这里有两个方法来实现,第一个是通过get_user_pages 函数,另一个是自己手动走页表,先介绍第一个:
case KVM_HC_EXPOSE_SHM: {
u64 gpa = a0;
int r = 0, nid = 0, npages = 4;
unsigned long shm_hva = 0;
void *shm_addr =0;
struct page **pages;
shm_hva = gfn_to_hva(vcpu->kvm, (gfn_t)(gpa >> 12));
pages = vmalloc(npages * sizeof(*pages));
down_read(¤t->mm->mmap_lock);
r = get_user_pages(shm_hva, npages, FOLL_WRITE, pages, NULL);
up_read(¤t->mm->mmap_lock);
if (r != npages) {
vfree(pages);
goto out;
}
nid = page_to_nid(pages[0]);
shm_addr = vm_map_ram(pages, npages, nid);
if (!shm_addr) {
vfree(pages);
goto out;
}
pr_info("[gz-debug]: %s\t%d\tContent from guest: %x %x %x\n",
__func__, __LINE__, *(int *)shm_addr,
*(int *)(shm_addr + (1 << 10)), *(int *)(shm_addr + (1 << 11)));
break;
}
如上面代码所示: 首先调用gfn_to_hva将gpa转化成hva, 再调用get_user_page将这1M内存pin在内存中(防止迁移与swap),此时KVM能够通过page结构体直接访问这块内存的页,为了更加简单的读写共享内存,我们使用vm_map_ram将pages结构体转化成连续的内核虚拟地址,此时Host(KVM)就能够通过这个地址直接访问共享内存。
(方法2)直接走页表
上面这个方法是将gpa转化成hva, 再对hva指向的用户态内存进行一些常规操作后在内核态访问,接下来这种方法是直接bypass hva,利用Stage2 page table将gpa直接翻译成hpa。
在hypercall里面将gpa转化成hpa,在转化成kernel可以直接读写的va。
case KVM_HC_EXPOSE_SHM: {
u64 gpa = a0;
void *shm_hpa =0, *shm_k_addr;
shm_hpa = (void *)get_hpa_from_gpa(vcpu, gpa);
shm_k_addr = __va(shm_hpa);
pr_info("%s\t%d\tgpa: %llx\thpa: %llx\tkernel va: %llx\n",
__func__, __LINE__, gpa, (u64)shm_hpa, (u64)shm_k_addr);
pr_info("%s\t%d\tContent from guest: %x %x %x\n",
__func__, __LINE__, *(int *)shm_k_addr,
*(int *)(shm_k_addr + (1 << 10)), *(int *)(shm_k_addr + (1 << 11)));
break;
}
这个方法的关键是走Stage2 page table: 首先需要拿到Stage2 page table的基地址和页表的级数。然后再逐级走页表,拿到最后的物理地址。
u64 get_hpa_from_gpa(struct kvm_vcpu *vcpu, gpa_t gpa)
{
u64 *eptp, epte, epte_idx;
u64 ret;
int cur_level;
epte = 0;
epte_idx = 0;
ret = 0;
eptp = __va(vcpu->arch.mmu->root.hpa & SPTE_BASE_ADDR_MASK);
cur_level = vcpu->arch.mmu->root_role.level;
while (cur_level > 0) {
epte_idx = SPTE_INDEX(gpa, cur_level);
epte = *(eptp + epte_idx);
if(!is_shadow_present_pte(epte)) {
printk("Error! ept entry is empty\n");
break;
}
if(cur_level == 2 && !!(epte&PT_PAGE_SIZE_MASK)){
printk("large page!\n");
cur_level--;
}
if (cur_level != 1)
eptp = __va(epte & SPTE_BASE_ADDR_MASK);
cur_level--;
}
if (cur_level == 0)
ret = epte & SPTE_BASE_ADDR_MASK;
return ret;
}
(方法3) 修改页表增加映射
上述的两种方法(通过hva和走页表)的前提是这个gpa到hpa的映射是存在于第二级页表的,我们只能够通过在Guest侧指定共享内存的gpa,而无法在Host侧指定共享内存存在于一个特定的hpa。为了解决这个问题,实现hpa first,可以采用第三种方法,在Host侧为Guest传过来的一个尚未有第二级页表映射的gpa映射到我们指定的hpa上。
Guest:
void expose_shm(void)
{
u64 shm_gpa, shm_gva;
/*
* PA: 1G
* the gpa has no mapping in the second level page table,
* but the hypervisor will help to add new map for the invalid gpa.
*/
shm_gpa = 1;
shm_gpa = shm_gpa << 30;
shm_gva = (u64)__va(shm_gpa);
pr_info("[gz-debug]: %s\t%d\tgva: %llx\tgpa: %llx\n",
__func__, __LINE__, shm_gva, shm_gpa);
kvm_hypercall1(KVM_HC_EXPOSE_SHM, shm_gpa);
pr_info("%s %d Content from KVM: %x %x %x\n",
__func__, __LINE__, *(int *)shm_gva, *(int *)(shm_gva + (1 << 4)),
*(int *)(shm_gva + (1 << 6)));
}
Guest 不再像之前一样通过kmalloc一段地址得到gpa,并写这块内存,因为如此的话,kvm会在处理第二阶段页表缺页(AMD里面叫做npf)的时候增加第二阶段页表的映射,之后我们再直接改页表就会与KVM自己的映射发生冲突。这里Guest直接拿一个gpa,然后调用hypercall让KVM增加映射。
Host:
static void map_shm_ept(struct kvm_vcpu *vcpu, gpa_t gpa, phys_addr_t hpa)
{
int cur_level;
int epte_idx;
u64 *eptp;
u64 epte;
struct page *new_page;
cur_level = vcpu->arch.mmu->root_role.level;
eptp = __va(vcpu->arch.mmu->root.hpa & SPTE_BASE_ADDR_MASK);
while (cur_level > 0) {
epte_idx = SPTE_INDEX(gpa , cur_level);
epte = *(eptp + epte_idx);
if (cur_level == 1) {
//BUG_ON(is_shadow_present_pte(epte));
printk("epte: %llx\n", epte);
*(eptp + epte_idx) = hpa | 0xff7;
break;
}
if(!is_shadow_present_pte(epte)) {
new_page = alloc_page(GFP_KERNEL | __GFP_ZERO);
epte = (page_to_phys(new_page) & SPTE_BASE_ADDR_MASK) | 0x107;
*(eptp + epte_idx) = epte;
}
eptp = __va(epte & SPTE_BASE_ADDR_MASK);
cur_level--;
}
}
ase KVM_HC_EXPOSE_SHM: {
u64 gpa = a0;
void *shm_k_addr;
phys_addr_t shm_hpa;
shm_k_addr = kmalloc(0x1000, GFP_KERNEL);
shm_hpa = virt_to_phys(shm_k_addr);
map_shm_ept(vcpu, gpa, shm_hpa);
pr_info("%s\t%d\tgpa: %llx\thpa: %llx\tkernel va: %llx\n",
__func__, __LINE__, gpa, (u64)shm_hpa, (u64)shm_k_addr);
*(int *)shm_k_addr = 0x1111;
*(int *)(shm_k_addr + (1 << 4)) = 0x2222;
*(int *)(shm_k_addr + (1 << 6)) = 0x3333;
pr_info("%s\t%d\tContent to guest: %x %x %x\n",
__func__, __LINE__, *(int *)shm_k_addr,
*(int *)(shm_k_addr + (1 << 4)), *(int *)(shm_k_addr + (1 << 6)));
break;
}
Host在hypercall中将gpa和一个hpa的映射添加到第二阶段页表中,这里我使用了一个任意的hpa,也可以自己指定一个具体的hpa。
共享内存验证
上面三种方案的代码均通过验证,可以直接使用。其实第一种方案与硬件架构无关,第二三种方案因为要读写页表,与硬件相关,我实现的是x86架构的。
启动虚拟机,可以在Host的dmesg和Guest的启动log中检查共享内存是否建立成功:


其他
上面的方法是基于Guest主动发起一个hypercall来共享某块内存的,但是这个方法有一个缺陷: 需要在虚拟机启动并发hypercall之后KVM才能够使用共享内存并写数据,有没有可能在虚拟机启动之前KVM就找到了共享内存,并提前在里面放了数据?当然也可以,我们能够让QEMU在启动的时候选择特定的gpa作为参数调用KVM的ioctl来将共享内存的hva告诉KVM。这一部分可以参考代码, 不在此展开。
参考
https://github.com/iaGuoZhi/linux/tree/kvm_shm_hc_guest
https://github.com/iaGuoZhi/linux/tree/kvm_shm_hc_host
https://github.com/iaGuoZhi/linux/tree/kvm_shm_hc_walk_host
https://github.com/iaGuoZhi/linux/tree/add_stage2_mapping_guest
https://github.com/iaGuoZhi/linux/tree/add_stage2_mapping_host
https://github.com/iaGuoZhi/Virtualization/tree/master/host-guest-shm
https://www.cnblogs.com/LoyenWang/p/13943005.html
https://zhuanlan.zhihu.com/p/530963525