iaGuoZhi
Xv6 页表介绍
页表是操作系统用来给每一个进程独立的地址空间和内存的机制。一般来说,页表以及其提供的虚拟内存机制为操作系统提供了以下功能:
- 缓存磁盘数据(swap,page cache)。
- 管理内存: a. 简化连接: 允许每个进程的内存映像使用相同的基本格式(ELF). b. 简化加载: 允许操作系统以lazy的策略加载目标文件. c. 简化共享:静态库,动态库,进程fork时候的copy on write. d. 简化内存分配: 以indirection的方式让进程看到连续的地址空间。
- 内存保护: 通过页表的pte bit位进行访问控制,从而提供不同进程之间的隔离。
在Xv6中,页表提供了管理内存与保护内存的功能。
Xv6 跑在Sv39 RISC-V上,这意味着虚拟地址的64个bit只使用了0-38这39个bit。 从下面这张图可以看出Xv6上的page table采用三级架构。 每一级页表大小位512*8=4096 bytes(4k), 每个页表上有512个entry,每个entry里面有PPN和Flags,PPN(44个bits)作为物理地址用来查找下级页表或者最终翻译结果的物理地址,Flags(10个bits)用来设置页表的权限。 Xv6中用到的权限位包括PTE_V,PTE_R,PTE_W,PTE_X,PTE_U。
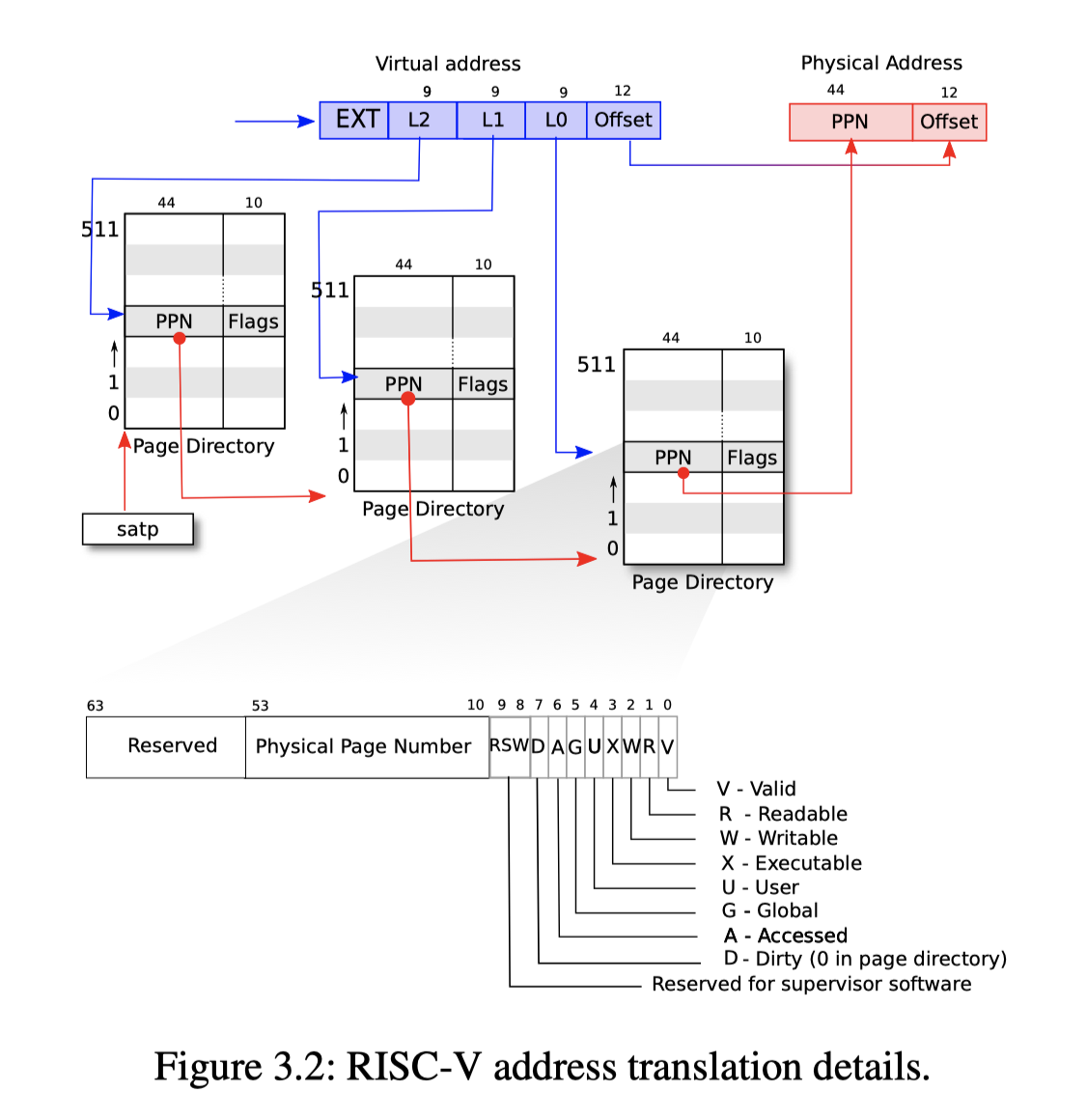
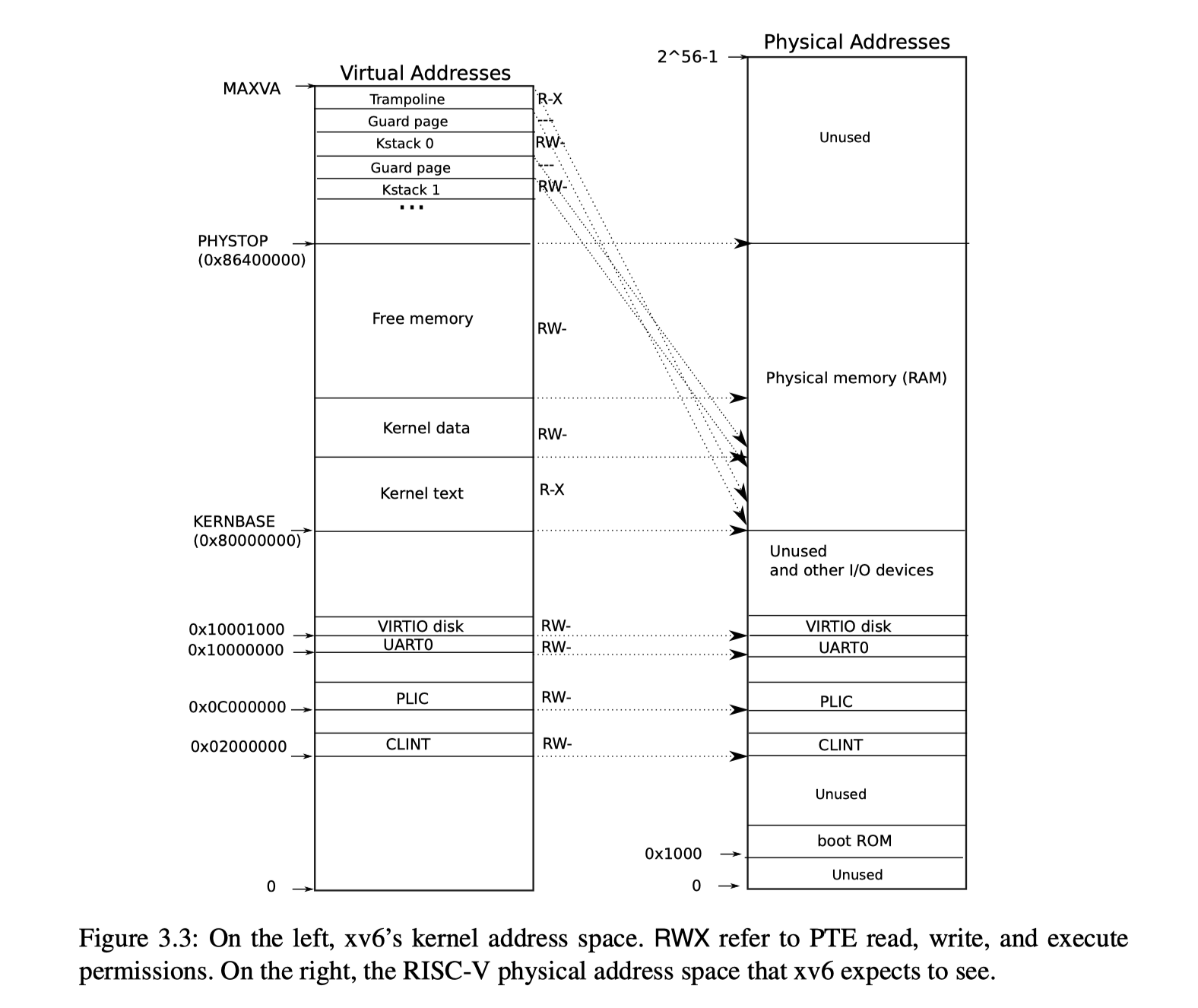
Xv6为一个进程提供了一个用户态页表,并且在内核实现了一个公共的内核页表(在这个lab中,我们需要为每个内核实现独立的页表)。下图是Xv6 book提供的关于Xv6 虚拟内存到物理内存映射关系图,可以看到,内核态的虚拟地址处于高地址,而每个进程的用户态虚拟地址空间将被映射在低地址(从0开始)。对于QEMU提供的寄存器和内核代码段,数据段,Xv6采用了直接映射的方式。
打印页表(简单)
pgtbl lab的第一个任务是在拿到内核页表基地址后,将整个页表打印为如下格式:
page table 0x0000000087f6e000
..0: pte 0x0000000021fda801 pa 0x0000000087f6a000
.. ..0: pte 0x0000000021fda401 pa 0x0000000087f69000
.. .. ..0: pte 0x0000000021fdac1f pa 0x0000000087f6b000
.. .. ..1: pte 0x0000000021fda00f pa 0x0000000087f68000
.. .. ..2: pte 0x0000000021fd9c1f pa 0x0000000087f67000
..255: pte 0x0000000021fdb401 pa 0x0000000087f6d000
.. ..511: pte 0x0000000021fdb001 pa 0x0000000087f6c000
.. .. ..510: pte 0x0000000021fdd807 pa 0x0000000087f76000
.. .. ..511: pte 0x0000000020001c0b pa 0x0000000080007000
由于Xv6中已经有递归释放页表的函数进行参考,这个任务比较简单。我实现该任务的主要函数如下: 因为Xv6 每个页表中有512个entry,因此这个函数会遍历512次,访问每个entry。只有entry中PTE_V为1的时候,才表明当前entry是有效的。由于最有一级页表的flag会设置PTE_R等权限位(不存在同时不能够读,写,执行的物理页),因此可以通过这些flag判断当前是否是最后一级页表,如果不是,则递归打印当前页表项所指向的次级页表。
void
static print_single_line(int level, int idx, pte_t pte, uint64 pa);
// Recursively print page-table pages
void
static __vmprint(pagetable_t pagetable, int level)
{
int i;
// there are 2^9 = 512 page-table pages.
for(i = 0; i < 512; ++i){
pte_t pte = pagetable[i];
uint64 child = PTE2PA(pte);
if(pte & PTE_V){
print_single_line(level, i, pte, child);
if((pte & (PTE_R|PTE_W|PTE_X)) == 0){
// this PTE points to a lower-level page table.
__vmprint((pagetable_t)child, level + 1);
}
}
}
return;
}
每个进程一个内核页表(困难)
目前,Xv6在内核态只有一个kernel page table。并且kernel page table的映射方式是direct mapping(va=pa)。而Xv6每个进程都拥有一个独立的用户态页表,此时如果内核想要使用一个来自进程用户态的指针,内核需要以软件的方式走一次该进程的用户态页表,我们需要在现在和后面的任务中实现内核对于用户态指针的直接访问。
现在这个任务需要实现的是让每个进程都拥有一个独立的内核页表。
初始化内核页表
首先在进程的结构体里面添加kenrel pagetable的字段:
pagetable_t kpagetable; // Kernel page table
kpagetable将在allocproc函数中进行初始化。
p->kpagetable = kvminit_perproc();
kvminit_perproc() 将对进程的内核态页表进行初始化:包括映射uart寄存器,virtio disk寄存器,PLIC终端控制器,内核代码段,数据段,trampoline页。kvminit_perproc和kvminit的区别是没有映射CLINT中断寄存器,为什么没有映射在下个任务的讲解会提到。
/*
* create a kernel page table for each process.
*/
pagetable_t
kvminit_perproc(void)
{
pagetable_t p;
// Alloc page table
p = (pagetable_t) kalloc();
memset(p, 0, PGSIZE);
// uart registers
kvmmap_perproc(p, UART0, UART0, PGSIZE, PTE_R | PTE_W);
// virtio mmio disk interface
kvmmap_perproc(p, VIRTIO0, VIRTIO0, PGSIZE, PTE_R | PTE_W);
// PLIC
kvmmap_perproc(p, PLIC, PLIC, 0x400000, PTE_R | PTE_W);
// map kernel text executable and read-only.
kvmmap_perproc(p, KERNBASE, KERNBASE, (uint64)etext-KERNBASE, PTE_R | PTE_X);
// map kernel data and the physical RAM we'll make use of.
kvmmap_perproc(p, (uint64)etext, (uint64)etext, PHYSTOP-(uint64)etext, PTE_R | PTE_W);
// map the trampoline for trap entry/exit to
// the highest virtual address in the kernel.
kvmmap_perproc(p, TRAMPOLINE, (uint64)trampoline, PGSIZE, PTE_R | PTE_X);
return p;
}
在allocproc创建进程的过程中还需要进行内核栈的分配与映射。注意这里不仅需要在进程私有的内核页表中建立va到pa的映射,还需要在进程共享的内核页表(在调度的时候使用到)中建立栈va到pa的映射。后面这一点是我在这个任务中花时间最多的一点。如果没有建立后者的映射,第一个用户程序刚启动的时候就会在调度器中跑飞,很难通过gdb或者打印的方式找到原因。
// Allocate a page for the process's kernel stack.
// Map it high in memory, followed by an invalid guard page.
pa = kalloc();
if(pa == 0)
panic("kalloc");
va = KSTACK((int)(p - proc));
kvmmap_perproc(p->kpagetable, va, (uint64)pa, PGSIZE, PTE_R | PTE_W);
// Map stack page in kernel_pagetable
kvmmap(va, (uint64)pa, PGSIZE, PTE_R | PTE_W);
p->kstack = va;
更改调度器
在每个进程拥有独立的内核页表之前,调度器在内核态切换进程的时候不需要切换页表。而现在每个进程拥有不同的内核页表,自然调度器也需要有对应的改动。
当选中一个进程执行的时候,需要通过将该进程的内核态页表基地址写入satp寄存器(satp 全名supervisor address translation and protection, 它保存页表基地址)。
在进程执行结束回到调度器时,调度器会将页表基地址设置为进程共享的内核页表,因为它能够访问所有进程的内核栈。
w_satp(MAKE_SATP(p->kpagetable));
sfence_vma();
swtch(&c->context, &p->context);
// Process is done running for now.
w_satp(MAKE_SATP(kernel_pagetable));
sfence_vma();
回收进程页表
此时进程的内核态页表指向的物理地址分为两种:一种是与其他进程共享,比如uart寄存器,virtio disk寄存器,这些物理地址被所有的进程共同访问。另外一种是只有该进程能够访问,这就是进程的内核栈。 在回收进程页表的时候需要对这两种情况区别对待, 第一种只需要回收页表内存,不能够free页表指向的物理内存,第二种则需要free页表指向的物理页。
可以使用uvmunmap函数中的do_free参数来满足我们的需求。对于内核栈内存,我们使用
uvmunmap(kernel_pagetable, va, npages, 1);
来回收页表,注意这里回收的是内核公共页表上进程内核栈对应的页表以及相应的物理内存。如此对于进程内核页表上的页表可以统一以不回收页表指向的物理页的方式对所有页表进行回收,简化代码逻辑。具体代码如下:
// Free kernel memory page table,
// not free physical pages
void
kvmfree(pagetable_t pagetable)
{
// there are 2^9 = 512 PTEs in a page table.
for(int i = 0; i < 512; i++){
pte_t pte = pagetable[i];
if((pte & PTE_V) && (pte & (PTE_R|PTE_W|PTE_X)) == 0){
// this PTE points to a lower-level page table.
uint64 child = PTE2PA(pte);
kvmfree((pagetable_t)child);
pagetable[i] = 0;
}
}
kfree((void*)pagetable);
}
简化copyin/copyinstr(困难)
上一个任务和这个任务的目的是让内核可以直接读用户指针。在上一个任务中我们已经为每一个进程创建了一个独立的内核态页表。在现在这个任务中我们需要在进程的内核态页表中映射上用户态页表中va到pa的映射。
由于此时内核态页表同时存在用户态虚拟地址与内核虚拟地址,我们需要保障这两种虚拟地址不会发生重叠。
更改copyin和copyinstr
首先将原来的copyin和copyinstr中手动走页表的逻辑删除,改写成调用Xv6已经提供了的copyin_new和copyinstr_new。
更改fork
在之前fork的实现中,只需要将parent的用户态页表深拷贝一份到child的用户态页表中,现在我们还需要将parent的用户态页表拷贝到child的内核态页表中。此时child的用户态页表和内核态页表应当指向同一块物理内存。
上述拷贝是通过uvmcopy这个函数实现的:
int
uvmcopy(pagetable_t old, pagetable_t new, pagetable_t new_kernel, uint64 sz)
{
pte_t *pte;
uint64 pa, i;
uint flags;
char *mem;
for(i = 0; i < sz; i += PGSIZE){
if((pte = walk(old, i, 0)) == 0)
panic("uvmcopy: pte should exist");
if((*pte & PTE_V) == 0)
panic("uvmcopy: page not present");
pa = PTE2PA(*pte);
flags = PTE_FLAGS(*pte);
if((mem = kalloc()) == 0)
goto err;
memmove(mem, (char*)pa, PGSIZE);
if(mappages(new, i, PGSIZE, (uint64)mem, flags) != 0){
kfree(mem);
goto err;
}
if(mappages(new_kernel, i, PGSIZE, (uint64)mem, (flags | PTE_U) - PTE_U) != 0){
kfree(mem);
goto err;
}
}
return 0;
err:
uvmunmap(new, 0, i / PGSIZE, 1);
uvmunmap(new_kernel, 0, i / PGSIZE, 1);
return -1;
}
更改exec
和fork一样,exec也需要为当前进程创建一个新的页表。
// Alloc new user page table
if((pagetable = proc_pagetable(p)) == 0)
goto bad;
// Alloc new kernel page table
if((kpagetable = kvminit_perproc()) == 0)
goto bad;
我们应当在每次用户页表发生更改的时候将更改同步到该进程的内核态页表中。exec有两处对用户态页表建立的新映射,第一次是加载可执行文件到内存中时, 第二次是在为进程分配用户栈时。我们需要在这两处地方都将对应va到pa的映射写入内核态页表中。
通过uvmalloc函数可以实现在给用户态页表建立映射的时候,将相同映射也写入内核态页表中。
// Allocate PTEs and physical memory to grow process from oldsz to
// newsz, which need not be page aligned. Returns new size or 0 on error.
uint64
uvmalloc(pagetable_t u_pagetable, pagetable_t k_pagetable, uint64 oldsz, uint64 newsz)
{
char *mem;
uint64 a;
if(newsz < oldsz)
return oldsz;
// user process memory size limit
if(newsz > USER_VA_STOP)
return 0;
oldsz = PGROUNDUP(oldsz);
for(a = oldsz; a < newsz; a += PGSIZE){
mem = kalloc();
if(mem == 0){
uvmdealloc(u_pagetable, k_pagetable, a, oldsz);
return 0;
}
memset(mem, 0, PGSIZE);
if(mappages(u_pagetable, a, PGSIZE, (uint64)mem, PTE_W|PTE_X|PTE_R|PTE_U) != 0){
kfree(mem);
uvmdealloc(u_pagetable, 0, a, oldsz);
return 0;
}
if(mappages(k_pagetable, a, PGSIZE, (uint64)mem, PTE_W|PTE_X|PTE_R) != 0){
kfree(mem);
uvmdealloc(u_pagetable, k_pagetable, a, oldsz);
return 0;
}
}
return newsz;
}
此时,当前进程的内核态页表中不仅有kvminit_perproc中指向内核物理地址的映射,也有和用户态页表指向用户态物理地址的映射。但是此时还不意味着我们现在的内核态页表就能够被写入satp寄存器来使用了(我之前没有仔细考虑这里,导致debug时间大幅增加)。如果我们将此时的内核态页表写入satp寄存器继续执行会遇到什么呢?程序根本不能够访问到当前exec()函数中分配在栈上的变量。因为新的内核态页表没有从旧的内核态页表中拷贝指向当前内核栈的物理页的页表。因此还需要一行代码:
// Map origin kernel stack
kvmmap_perproc(kpagetable, p->kstack, kvmpa(p->kstack), PGSIZE, PTE_R | PTE_W);
现在,在exec函数的最后,我们可以使用新的内核态页表了:
// Commit kernel page table
oldkpagetable = p->kpagetable;
p->kpagetable = kpagetable;
w_satp(MAKE_SATP(p->kpagetable));
sfence_vma();
proc_freekpagetable(oldkpagetable);
通过将新的内核态页表写入satp寄存器,它就正式被派上用场了,这时候我们还需要对旧的内核页表进行回收。
更改sbrk
用户程序可以通过sbrk来增加用户态地址空间。我们需要将sbrk中对于用户态页表的修改同步到内核态页表中。
sbrk通过调用growproc来调整地址空间大小。更改后的growproc如下:
// Grow or shrink user memory by n bytes.
// Return 0 on success, -1 on failure.
int
growproc(int n)
{
uint sz;
struct proc *p = myproc();
sz = p->sz;
if(n > 0){
if((sz = uvmalloc(p->pagetable, p->kpagetable, sz, sz + n)) == 0) {
return -1;
}
} else if(n < 0){
sz = uvmdealloc(p->pagetable, p->kpagetable, sz, sz + n);
}
p->sz = sz;
return 0;
}
growproc会调用uvmalloc,uvmalloc的代码我们已经展示过了。里面有一个细节跟sbrk有关:
// user process memory size limit
if(newsz > USER_VA_STOP)
return 0;
这里会检查sbrk修改后的用户态地址空间大小,如果超过了限制,就直接返回。这是为了防止内核页表上用户态地址空间与内核态地址空间出现重叠的情况。
USER_VA_STOP在我的实现中是0x07000000L, 它大于CLINT直接映射的虚拟地址0x2000000L。如此进程能够拥有更大的用户态地址空间,因为实际上CLINT在Xv6中只与处理timer中断有关,而处理timer中断时用到的页表是内核公共的页表,因此进程的内核页表上不需要映射CLINT寄存器,于是USER_VA_STOP即使大于CLINT,在进程内核页表上用户态地址空间与内核地址空间也不会发生冲突。
总结
这个Lab要比之前两个Lab困难很多,需要完全理解地址空间布局才能够少踩坑。我在这个Lab上花费的时间要多上很多:
参考
https://pdos.csail.mit.edu/6.828/2020/labs/pgtbl.html
https://pdos.csail.mit.edu/6.828/2020/xv6/book-riscv-rev1.pdf
https://csapp.cs.cmu.edu/